
声音素材准备,把歌曲的背景音乐去除,使用Ultimate Vocal Remover。需要使用两次,第一次比较快,去除伴奏,第二次稍微慢一点,去除和声和混响,实践证明先后用以下两个模型可以有效解决人声忽高忽低的问题。补充:如果前两次处理后还有混响和部分和声,需要再用第三个模型处理一遍。三次的参数如下:
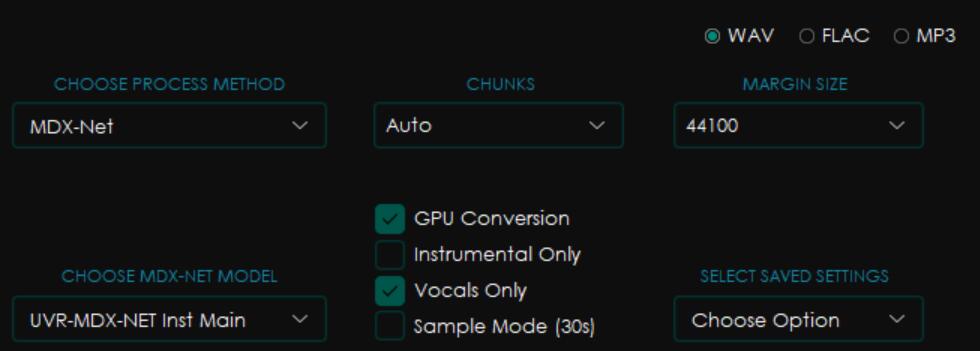
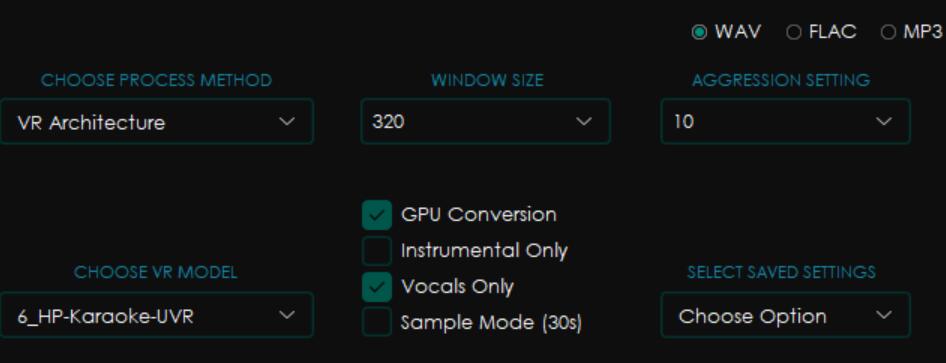
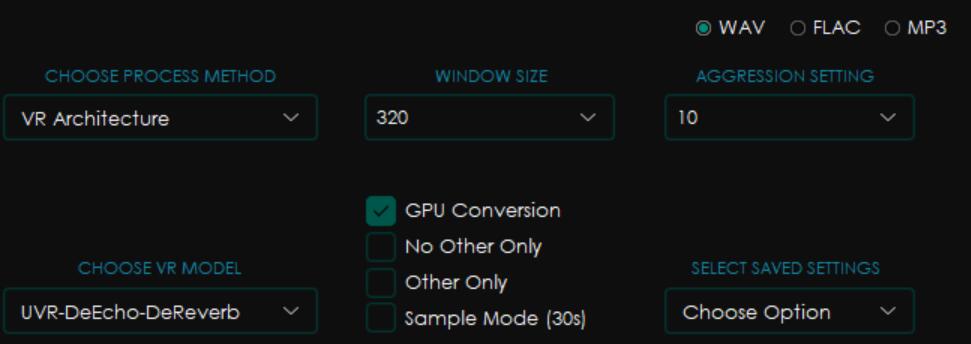
使用整合包里的小工具把纯人声进行分割处理,整合包地址:https://www.bilibili.com/video/BV1H24y187Ko/?spm_id_from=333.1007.top_right_bar_window_default_collection.content.click&vd_source=9025a814aaf3e9e51efe4c85d387002b
把分割后的所有文件放到dataset_raw目录下,并新建一个文件夹,把所有文件都统一改名,最好是数字序列作为文件名,有符号会报错。注意每个文件都要试听,把质量差的,声音飘忽不定的都务必删掉,要不会影响最后的模型质量,宁缺毋滥。
进入webui,训练标签,按步骤执行,注意批量大小那里根据显存来写,要不会爆显存
进行训练,不会自动停止,在命令行界面按ctrl+C手动停止,下次可以在web页面继续训练
推理的时候如果爆显存,需要手动设置音频自动切片的参数。