
Youtube长视频工具:超长文稿匹配
从今年5月份开始制作YouTube的长视频,到现在已经开通了6个YPP,RPM在4刀左右。中间经历了多轮的工具迭代,其中有一个痛点一直没有得到满足,就是长文本的文稿匹配,剪映只支持最长5000字,如果超过了,就得自己手动分段识别,然后一点点的调整对齐,做过的人都知道有多麻烦。
我的工作流程是:先AI生成文本,大概一万字左右,然后使用indexTTS进行克隆语音并朗读成音频,然后再将音频跟我的文本匹配输出SRT字幕。这样可以做到字幕没有任何错别字。如果是使用语音识别字幕,就会有很多错别字,对于我这种偏专业术语的内容,完全不可接受。
在网上找了很久,都没有找到合适的工具,也一直使用剪映人工分段识别并调整,但是最近文本越来越长,超过1万多字,剪映用起来就非常痛苦了,分段的不准的话匹配的字幕会乱飞,完全是浪费时间,于是使用cursor手搓了一个工具,迭代了几天,目前来看已经达到剪映90%功力了(当然5000字以下还是使用剪映比较快,但是剪映是在服务器端识别的,会受网络影响)。
工具的大概原理:
1、使用whisper识别语音成初步的字幕,这一步会有很多错别字
2、使用DTW算法把我提供的文本跟上一步识别的文字对比,并做修正
由于不止一个Python文件,不好贴在这里,想用的可以去GitHub拿:
https://github.com/blueslmj/txt2srt
附上工具的web UI界面:
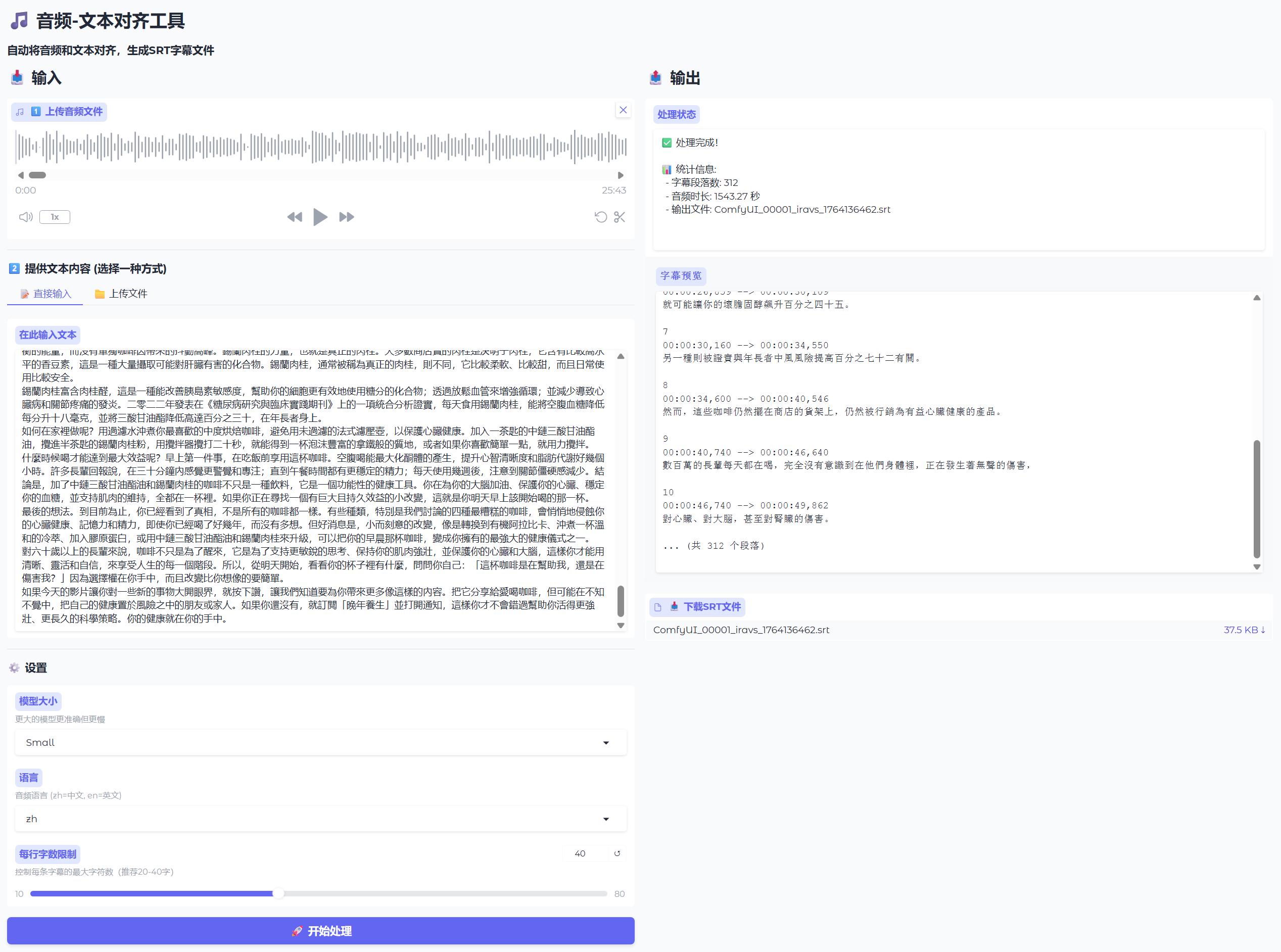
whisper的模型我用的small,测试了几个模型,这个综合下来最好用,识别准确率也够用,每一行的字符限制是40,也可以自行修改。
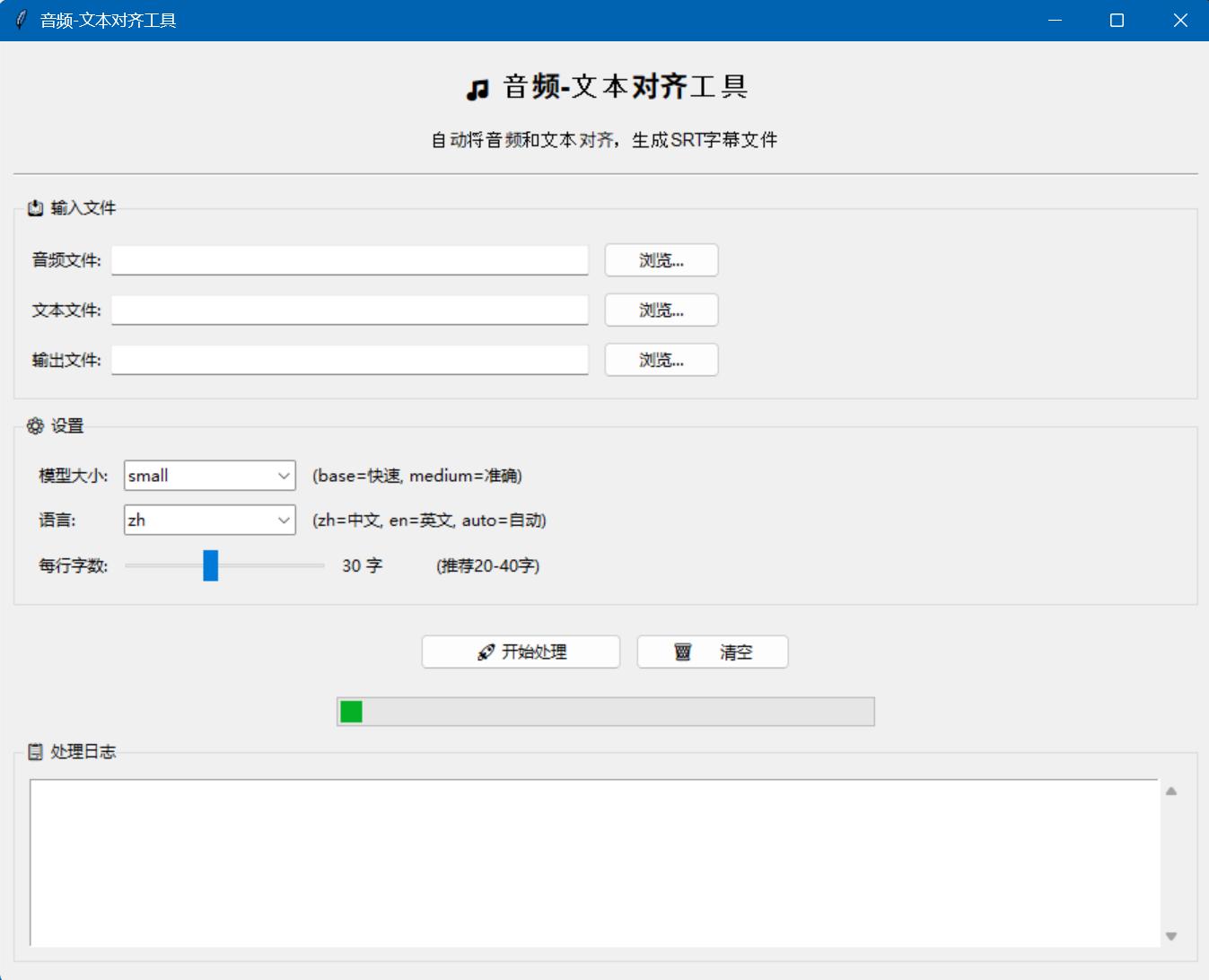
Windows的客户端也有,不过界面比较丑:
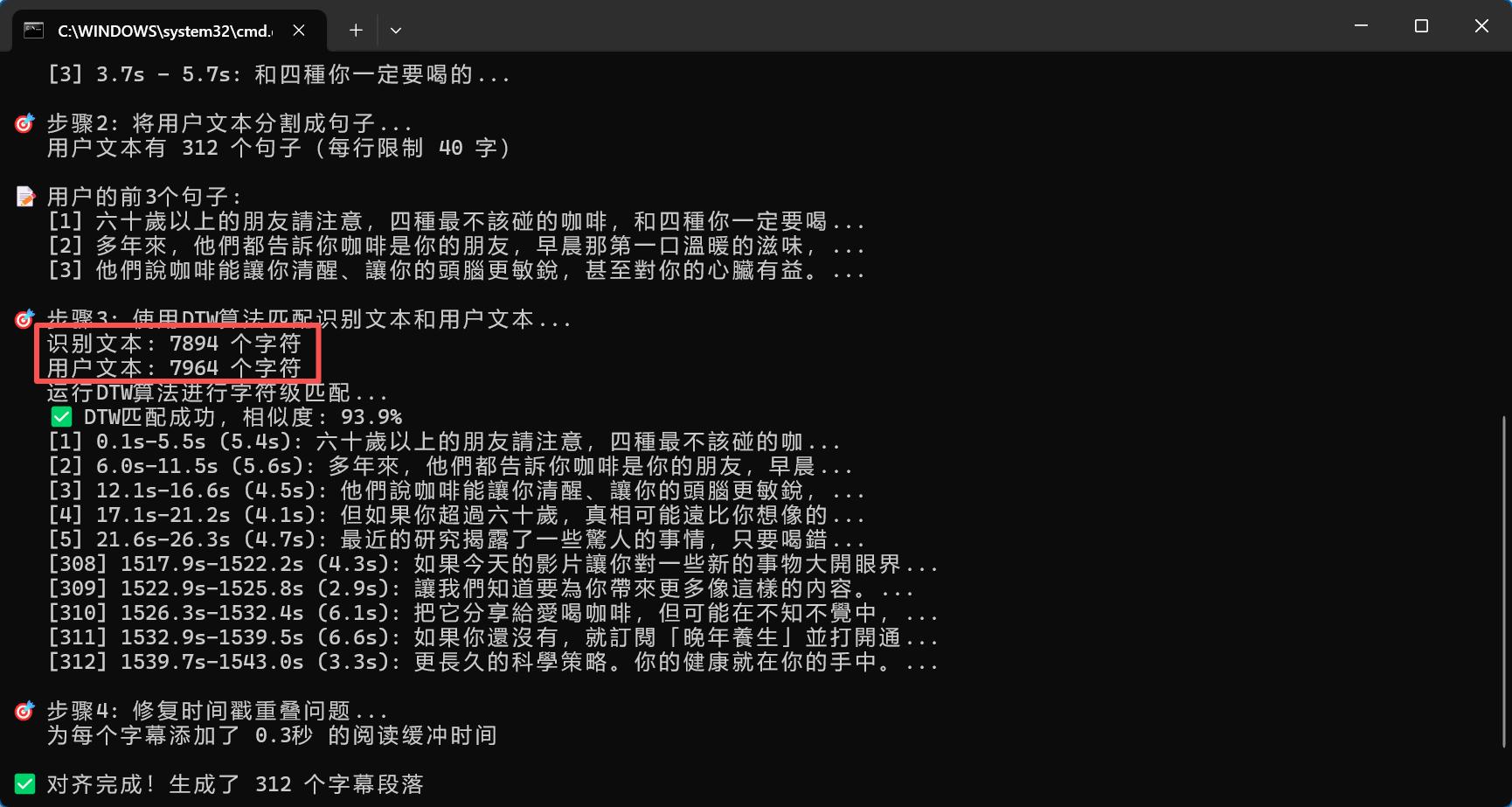
这是运行的终端界面,可以看到识别准确率还是不错的,完全可以代替剪映,并且支持无限长文本:
对了,我的显卡是5070ti,最新的pytorch不支持,如果是40系的话可以安装最新版的,速度会更快一些(所以我升级了个啥。。。)